背景:
- 视频capiton任务中,增加帧数和模型计算量相互制约。早前的视频caption模型对时间和空间维度的下采样损失了较多的信息(videochatgpt),导致模型capiton效果不佳(过短或幻觉)。
- 现有的video caption数据集质量不佳,通常capiton较短、或是以对话的形式。
- 各开源、闭源方案调研:GPT4-v > Qwen-vl-max > Pllava > Llama-VID > Cog-VLM。
贡献:
- 提出了一种pooling策略,使得模型在计算、训练效率和capiton效果间达到比较好的平衡。
- 提出post training的方法,对多模态大模型使用LoRA训练,减轻模型在finetune过程中的遗忘和退化问题,同时能够很好的适应到目标。
模型相关:
Pllava模型结构:
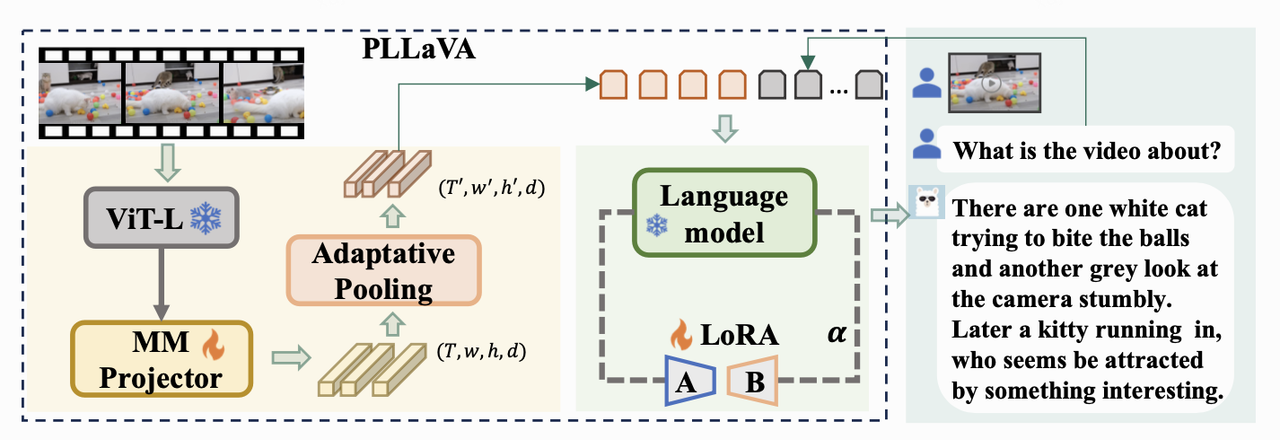
Llava:将输入图片通过图像预训练编码器(clip)得到图片特征,再经过线性映射将特征映射到文本特征空间,再经过LLM得到文本。 Pllava:在Llava的基础上,输入图片序列对输入的图片特征序列作3d pooling,得到的时间和空间的联合特征通过线性映射后,与文本特征concat送入LLM得到文本。
- 提出adaptative pooling结构:
- 先前两类工作存在的问题:认为之前多帧feat直接concat或者videochatgpt使用的时间空间pooling,对feat操作不佳,导致性能下降。其中多帧feat concat受限于计算量,可能导致信息不充分;时间空间的pooling可能会造成对feature的误处理。
- pooling前尺寸为 $(T, w, h, d)$ → pooling后尺寸为$(T’, w/2, h/2, d)$,其中 $T’$ 一般为16。原始输入为 16 * 336 * 336 * 3 , 经过 MM project之前的shape为 16 * 24 * 24 * d ,pooling之后为16 * 12 * 12 * d。
- 提出后训练优化:
- 先前工作的问题:认为先前工作出现的模型尺寸上升但是caption会变短且更差的问题,认为是image-LLM在低质量视频文本数据上训练导致的退化。
- 使用LoRA模块,结合初始权重的image-LLM,在视频数据上训练,并调整两部分参数输出的权重。实验表明,较低的LoRA部分的权重占比有更好的模型表现。整个网络在post training中训练的参数,仅为多模态projector和LLM中的LoRA (lora_alpha=32, lora_r=128, q_proj, k_proj)。 $$h = W_0X_{vp} + \frac{\alpha}{r}\Delta WX_{vp}$$ 其中 $∆W$ 为 $W_0$ 对应的low rank可学习权重,$ \frac{\alpha}{r} $ 用于调整学习到的低秩权重在输出中的占比。
实现细节:
- 数据:使用Qwen-vl-max,对目标数据域下Million量级的视频进行capiton(12s/video,每个视频抽四帧),基于这批数据进行Pllava模型的微调。
- 训练:使用 A800 2*8卡进行模型训练,单卡 batchsize为12。其中输入数据单个视频抽16帧,训练阶段一个step耗时20s左右。Million级别的目标域数据16卡训完一个epoch耗时约6天,实际训练数据过半后准确率基本不再下降保持稳定。
- 测试方法:从目标数据中选取500个视频作为测试集,使用gpt4_trubo对Ground truth(from qwen-vl-max)和 推理得到的caption进行语义相似评分,并评判capiton描述是否正确。
- 推理:A100 / 4090 机器下,单条视频16帧 6.02秒完整capiton生成。使用训得的Pllava13b模型完成后续动漫视频的capiton。
总结:
优势:
- 训得的模型在保持效果尽可能接近qwen-vl-max的基础上,在未经过多工程优化的情况下,推理耗时为平均每条视频6.02s,qwen-vl-max api耗时 12s。
- 采用的预训练模型架构在目前开源框架中是较为优秀的,在保留图片空间信息的同时获取时序上的信息,同时推理时间较短适合于批量打标。
- 相较于该框架下的开源预训练模型,经过微调后的模型获取了更多的先验知识,在我们的数据集上(特别是动漫数据下)拥有更好的表现效果。指标上,相较于开源模型准确率提高8个点,平均得分提高0.2分;主观上,caption幻觉减少,描述更加准确,理解能力变强。
待提升的点:
- 本身训练数据gt存在的幻觉可以进一步清洗,同时模型结构没有进行过多的优化。
- 推理部分可以通过一些加速优化方法进行加速。